
🎒 Resources
- GitHub Repository for Jenkins CI/CD Pipeline
- GitHub Repository for the iPhone Prices Scrapy Spider
- First Part of the Series: Introduction
In the first part of this tutorial, we have laid down the foundation of our web scraping project. We set up Jenkins and created a pretty harmless, but working Scrapy installation. In this part, we will explore Scrapy Shell and learn how to plan and execute a scraping project.
What Will We Scrape?
So as I mentioned earlier, now we have Scrapy working inside our Jenkins build agent. Let’s make it useful. We will scrape Apple’s website for the latest iPhone models and their prices.
Let’s say we want to find out the prices of an iPhone 15 Pro in the US, Sweden, or Hungary. Instead of manually checking each website, we can efficiently gather this data using a Scrapy Spider to organize it into a table format. But before we delve into the details, let’s begin with a solid plan! Shall we?
Using Scrapy Shell
With Scrapy Shell, you can interactively test your selectors and XPath expressions on the locally cached version of a single page. This allows us to refine our scraping logic efficiently, without the need to deploy a full spider or risk abusing an actual website.
Starting the Shell & Playing with Selectors
Let’s fetch the US Apple website and start the shell. We will use the scrapy shell command with the URL of the US Apple website.
| |
This will start the Scrapy Shell, fetch and cache the website, and give you a prompt to interact with the parsed content. For now, let’s skip all the messages and warnings Scrapy prints out and focus on the prompt. Let’s dip our toes in the water and check how Scrapy sees the website.
Execute the following command in the shell:
| |
This will open the locally cached version of the website in your default web browser. At first glance, it looks like the real thing, and you’re not wrong. It’s the same HTML, CSS, and JavaScript you would see in your browser. But verify the address bar of your browser. It should look something like this:
file:///private/var/folders/48/366gc36x3938161tl4831tz80000gn/T/tmppwf9cpz1.html
Indeed, the content is the same, but it’s not the live website. It’s a locally cached version of the website:
One thing to note here. In your browser - by default - JavaScript is executed and the website is rendered. In contrast, Scrapy only fetches the raw HTML and CSS. This is important to remember, as you will see later. So, how to make sure we are looking at the same thing as Scrapy? Let’s disable JavaScript in our browser:
Refresh the page and suddenly it looks like the page stopped working correctly:
No need to worry. What you’re viewing is the server-side rendered version of the website, where many details are processed using JavaScript on the client side. By disabling JavaScript, we ensure our view aligns with what Scrapy will capture. Browsing the website this way - relying only on the server-side rendered content - is far less satisfying compared to the full version, but still, we can access all the data we need: actual phone models, their prices, and so on. For more complex scraping jobs you should worry about client-side rendered content and go with a headless browser. However, it seems that Apple did a good job of serving the content to clients without JavaScript support.
Playing with Selectors
Now that we made sure we are on the same page (pun intended) with Scrapy, let’s specify the instructions on where to find the data we’re looking for.
With Scrapy, we can use CSS selectors or XPath expressions to find the elements we are interested in. Many developers prefer XPath, as it’s a robust, and more powerful solution than using CSS selectors. Since the task I want to accomplish is not too complex, I will use the latter one. Feel free to convert the examples to XPath if you prefer that.
Let’s make use of the Developer Tool in our browser to find the right selectors. Right-click on the element you are interested in and select “Inspect” from the context menu. Another way is to press Cmd + Shift + C on macOS or Ctrl + Shift + C on Windows or Linux. This will open the Developer Tools and highlight the element you hovered over.
Either way, let’s figure out the selector for the iPhone models’ price page. To achieve that, inspect a box with the name of a given model (anyone will do) with the blue Buy button on the right bottom corner:
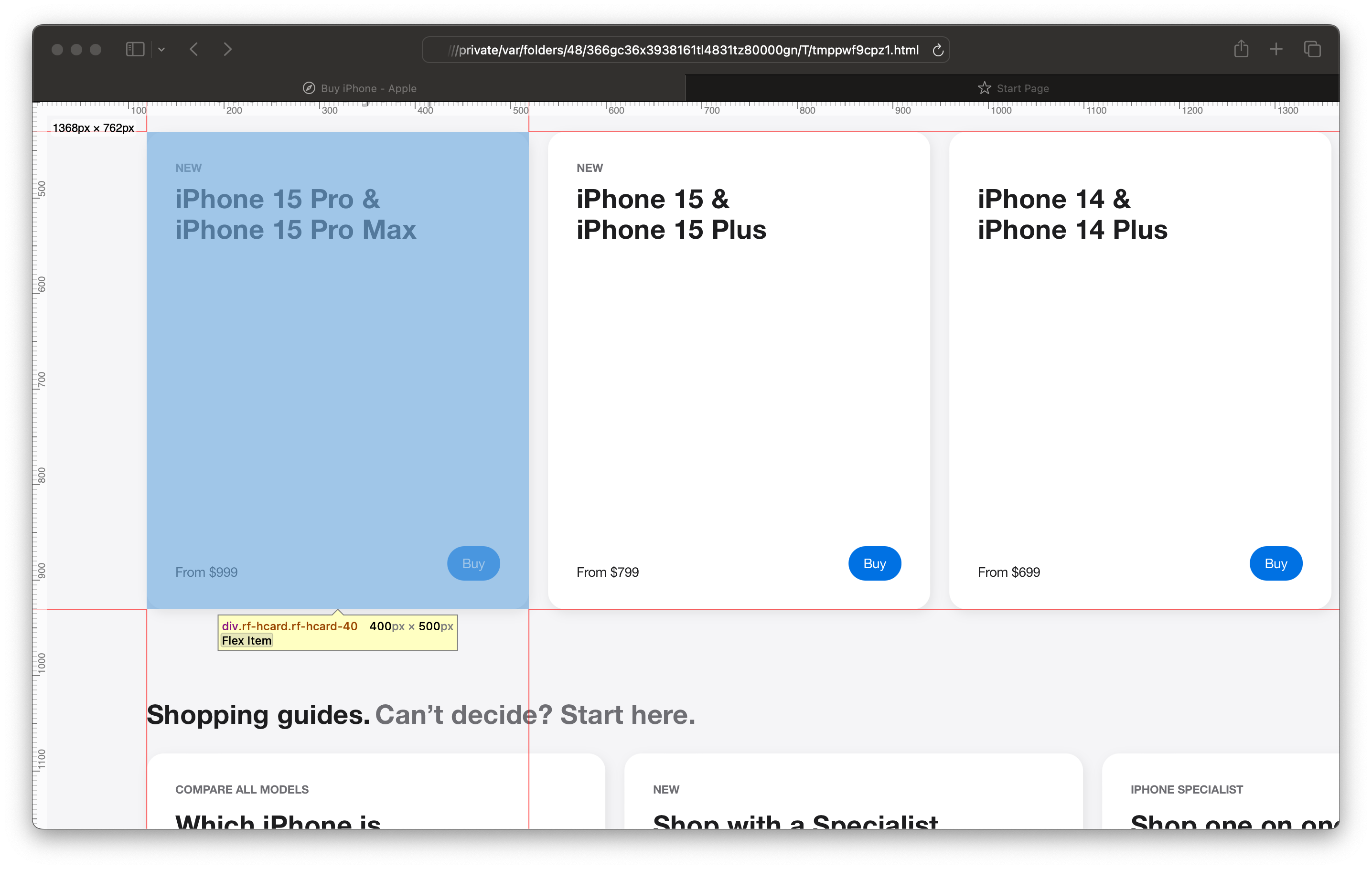
This div element should have an a tag inside it, like:
| |
We need to extract these links via their a tag’s href attribute. The a tag is located inside of a div with classes of rf-hcard and rf-hcard-40 respectively. We will work with this information.
Now switch back to the Scrapy Shell and execute this:
| |
The result should be a list of URLs, each pointing to a different iPhone model:
| |
Now ask Scrapy to fetch the page of a given model, for example, the iPhone 15 Pro:
| |
Now we have the iPhone 15 Pro’s page parsed into the response object. If you open the page in your browser (remember? view(response)), you will see something like this:
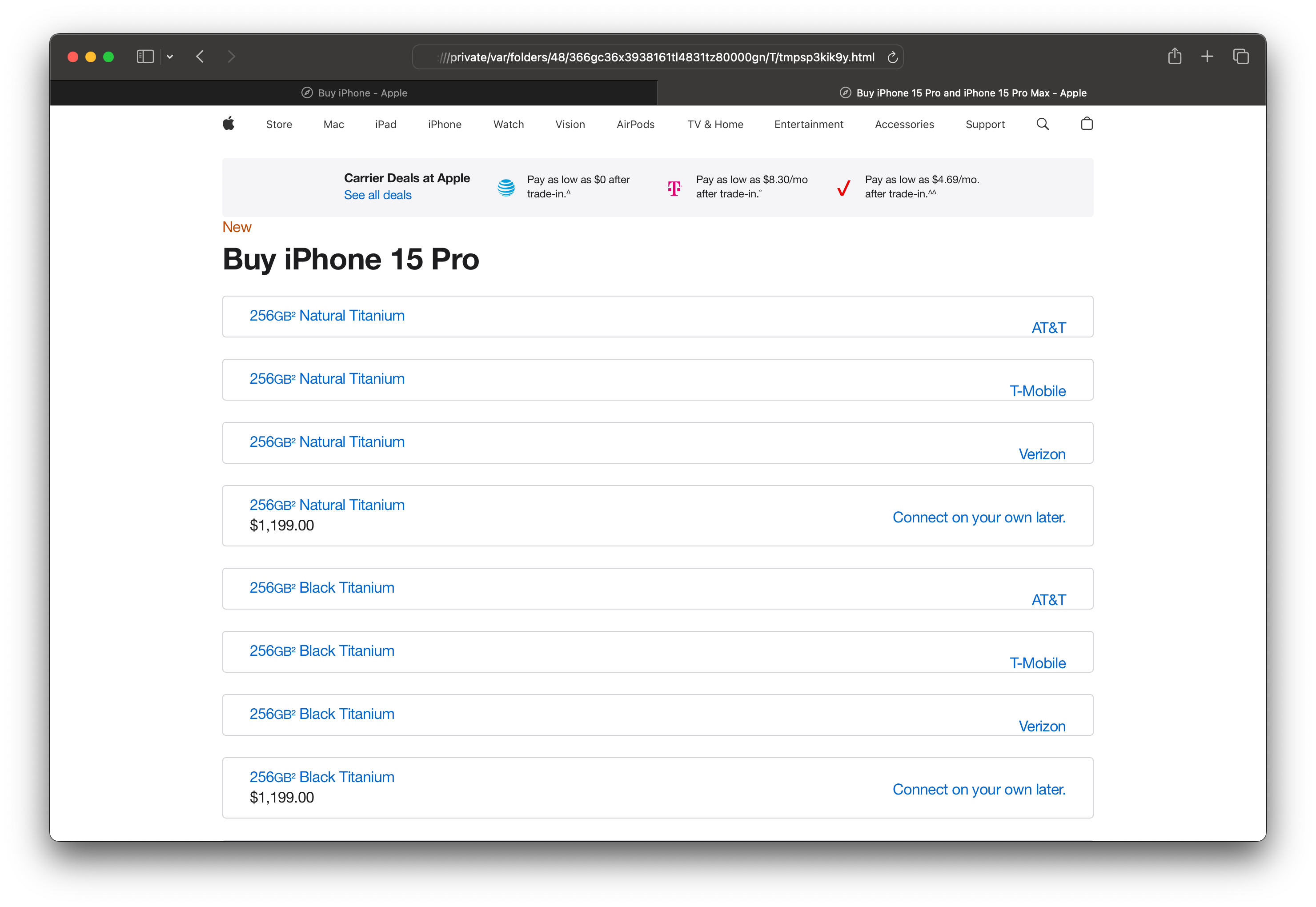
This page may look a bit awkward, but believe me, there is everything we need:
- the capacity
- the color
- and the most important piece of data: the price
You may notice that the price is not displayed for models sold by carriers. Because of that, we will focus on the SIM-free models only.
Let’s have a look at the boxes with a light gray border - they contain the aforementioned data for a phone model. If you look closely at the source, you can see that these boxes are div elements with the class of "details":
| |
A lot of span elements are here and as you can see, all of them have a self-explanatory class name. Good job, Apple! 👏
| Class name | Description |
|---|---|
dimensionCapacity | The capacity of the iPhone |
dimensionColor | The color of the iPhone |
current_price | The price of the iPhone |
We will use these class names to extract the data we need; please go back to the Scrapy Shell. First, fetch all the phone models and their details into a list:
| |
💾 Check the capacity of the first phone model:
| |
📐 How about the memory unit?
| |
🌻 Nice. Now let’s get the color of the iPhone:
| |
💰 And finally, the price:
| |
Oops! It appears that the price for this model is unavailable. Wondering why? Well, as mentioned earlier, prices aren’t listed for models sold by carriers. The first entry in the listing happens to be one such model (sold by AT&T). Let’s bypass that and jump straight to the 4th element in the listing:
| |
Much better. Needless to mention, our Spider will have to handle this situation and skip the models without a price. If you wish, you can play with the other models, with different countries’ websites, and so on (spoiler: our selectors should seamlessly work with every country-specific site and phone model 😉).
Take your time; I’ll be here waiting, ready to start building the Spider together in the next part of this tutorial. ⏩