
🎒 Resources
- GitHub Repository for Jenkins CI/CD Pipeline
- GitHub Repository for the iPhone Prices Scrapy Spider
- First Part of the Series: Introduction
- Second Part of the Series: Playing with Scrapy Shell
- Third Part of the Series: Creating a Scrapy Spider
👈 Previously we have created a Scrapy Spider that scrapes the Apple website for iPhone models and their prices. It has some issues that we need to fix before we can consider it a production-ready web scraping solution.
Let’s fix things step by step, shall we?
📐 Improving the Spider
We’ll begin by separating the helper functions from the main Spider code and placing them into a new file. This step will make our Spider more organized and easier to understand. Plus, it allows us to use these functions in other Spiders in the future. Please create a new Python file called spider_utils.py in the iphone_price_bot folder.
Next, we’ll standardize the colour names. Our goal is to have consistent colour names in English, regardless of the country. So, we’ll convert all colour names from Hungarian and Swedish to English.
| |
The translate_color_hu function is designed to convert Hungarian colour names into their English counterparts. If a colour name isn’t in our list, it keeps the name as is. This tool lets us match colours between Hungarian and American iPhone models without needing to translate each colour name by hand.
As you may have guessed, we need a similar function for the Swedish colour names. This function is called translate_color_se and it is very similar to the translate_color_hu function. I will put here nothing else, only the dictionary for the colour translations.
| |
Nice, we have the colour translation functions. Now, let’s organize our code by moving the country code extraction function into the spider_utils.py file. This function, named get_country_code, is similar to what we’ve seen before but now includes an extra part called loader_context.
This function will be used in the Item Loader to extract the country code from the URL of the page. The loader_context parameter is a dictionary that holds the context of the Item Loader. Don’t worry, we’ll go over Item Loaders in more detail soon.
| |
I hope you still remember why we have this "shop" string in the URL. Yeah, it’s indicates that we’re on the US Apple website.
Next, move our clean_value function to the spider_utils.py file. This function removes the leading and trailing empty-spaces and any non-ASCII characters from the value.
| |
Next, we’ll streamline the process we’ve been using to remove the word ‘Buy’ and its equivalents in Swedish and Hungarian from the model names. We’ve created a function named clean_model for this purpose.
| |
As you can see, we also cleaned the model name from any unwanted stuff. One small function here is to ensure the model capacity is free from unwanted characters (spaces and other blank characters).
| |
Pretty straightforward, right? Let’s move on and streamline our crawling logic with Item Pipelines.
🔁 Item Pipelines
Pipelines? You might be wondering if we’re discussing iPhone model scraping or constructing CI/CD pipelines here. Interestingly, the notion of processes executed in sequence isn’t limited to the realm of DevOps. It’s a good practice to delegate the tasks of manipulating and processing scraped data to distinct classes. When we call these classes ‘pipelines’, it leads us to the concept of Scrapy Item Pipelines.
🔍 Anatomy of a Scrapy Pipeline
A Scrapy pipeline is a Python class that processes items returned by the Spider. It can perform various tasks, such as cleaning, validating, and storing the scraped data. The pipeline class must implement the process_item method, which receives the item and the Spider instance as arguments. The method should return the processed item or raise a DropItem exception to discard the item.
You might already figure out that we are going to use this exception to filter out the models without prices.
Pipeline for Price Data Processing
Let’s start with delegating the task of processing price data to a dedicated pipeline. Add the following class to the pipelines.py script:
| |
This pipeline checks if the item has a "price" field. If it does, it melds the "capacity_unit" with the "capacity" field, then drops the "capacity_unit" field itself, finally returns the modified item. If the item does not have a "price" field, it raises a DropItem exception to discard the item.
Pipeline for colour Translation
Yes indeed, we are going to delegate the translation logic into a separate pipeline. Add the following class to the pipelines.py script:
| |
Are you satisfied with the convert_color method? Neither am I. Feel free to refactor it to your liking. Now let’s move on and see what is missing from our pipeline? Oh, I know! The price conversion logic. Let’s add a new pipeline for this task:
| |
Okay, that’s a bunch of code for a pipeline. Let’s break it down. The clean_currency method removes commas, currency symbols, and other unwanted characters from the price value. The convert_to_usd method converts the cleaned price to USD based on the country field of the item. The converted price is then assigned back to the price field of the item.
Summary of the Pipelines
So far so good, we have three items in our pipeline - let’s visualize them:
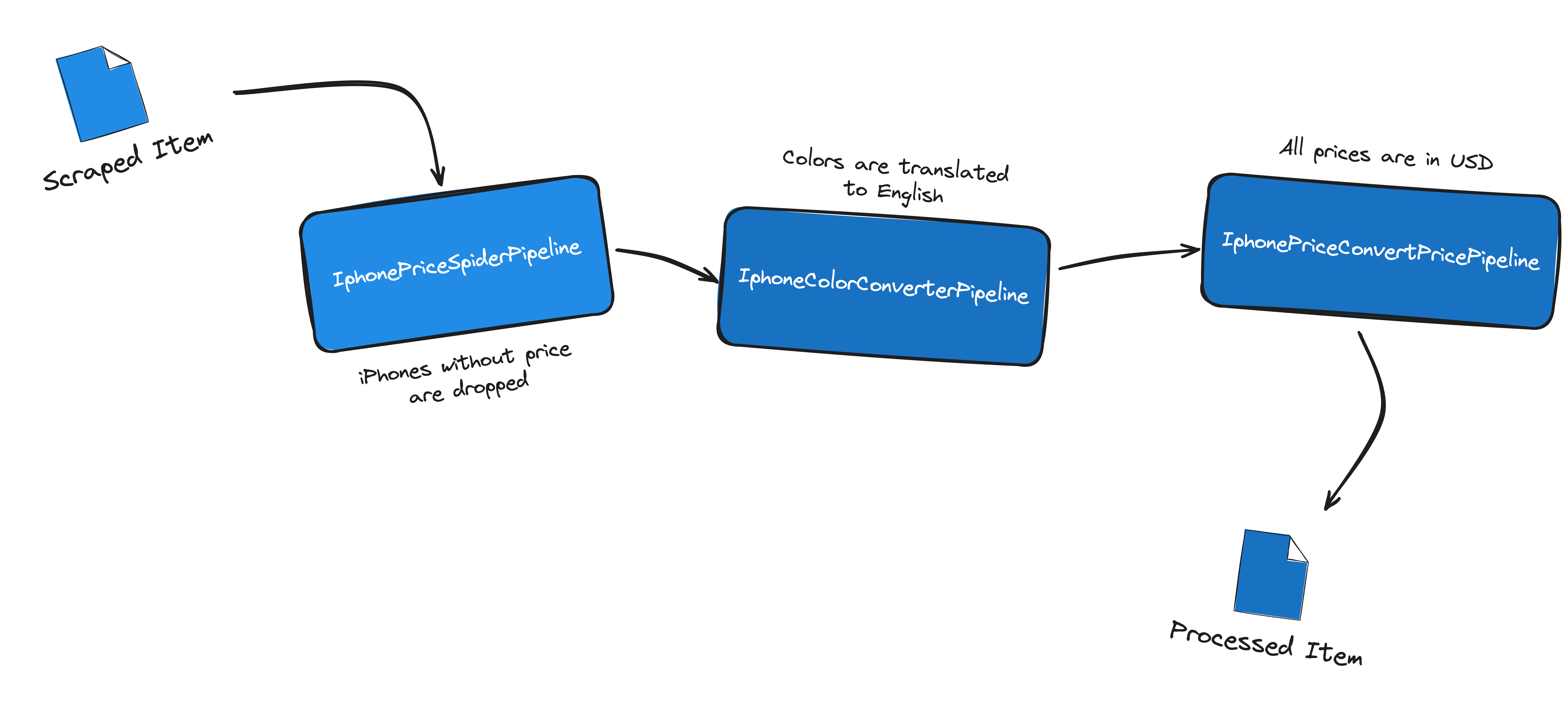
The Spider sends the scraped, “raw” data to the Item Pipelines.
- The
IphonePriceSpiderPipelineprocesses the data by merging the capacity unit with the capacity field. If the item does not have a price field, it raises aDropItemexception to discard the given item. - The
IphoneColorConverterPipelineconverts the color field to English based on the country field. - Finally, the
IphonePriceConvertPricePipelinedoes the same, but with the price field.
Enable the Pipelines
There’s still more to do! For Scrapy to utilize the pipelines we’ve crafted, we must activate them. This is done in the settings.py file. Please insert these lines into that file to get the pipelines up and running:
| |
The numbers assigned to each pipeline in the dictionary determine their execution sequence. A lower number means the pipeline runs sooner. You’re not bound to use the exact numbers I’ve chosen; adjust them as you see fit. It’s wise to space them out, perhaps in increments of 100, to allow painless insertion of new pipelines later on.
⬇️ Item Loaders
Item Loaders are a powerful Scrapy feature that simplifies the data extraction workflow. They allow you to define reusable input processors for your items. You can define these processors in a separate class and reuse them across different Spiders. Let’s see how we can use Item Loaders to fetch and clean properly the iPhone model data from Apple’s website.
Define the Item Loader
For our current project, we’ll integrate an Item Loader directly within the Spider. Please put the following class into your apple_website_spider.py script:
| |
Now, that’s not much, is it? The IphoneItemLoader class is a subclass of the ItemLoader class provided by Scrapy. We set the default_output_processor attribute to TakeFirst() - let me clarify the terms input and output processors a bit later. Trust me, it will make sense soon.
We are going to use this loader to extract the iPhone model data from the website. To fetch the URLs of the iPhone models, we still extract them using a CSS selector:
| |
Before we can use the IphoneItemLoader class, we need to make some changes to the parse_phone method:
| |
First, we create an instance of the IphoneItemLoader class, but what is this IponePricesItem? It’s the item class we have defined in the items.py file.
For a refresher, here is the original version of this class, as we defined it in the items.py file:
| |
Let’s move the cleaning logic from the Spider to the Item. Every Item Field can have exactly one input processor and one output processor. We can define these processors in the items.py file (or a set default one in the Item Loader, if it is more convenient - as we did above).
Here is the updated version of the IphonePricesItem class:
| |
The MapCompose function applies the given function to the input value. In this case, we use the functions we have defined in the spider_utils.py file to clean the model, capacity, and price fields. As I promised earlier, let’s clarify input and output processors.
Input and Output Processors
Input processors are functions that modify the data given to the Item Loader through methods like add_value, add_css, or add_xpath.
Once all the data is gathered and adjusted, we use output processors to finalize it. This is done by using the load_item method from the Item Loader. Recall how we set up a default output processor for the IphoneItemLoader class? It was the TakeFirst() processor, which selects the first valid value from the collected data.
Item Loader Context
If you look closely at the parse_phone method, you will see that we set the response_url key in the phone_loader.context dictionary.
What is this dictionary anyway? If we need to pass more data to input and output processors, we can use the context dictionary. In our case, we pass the URL of the response to the get_country_code function. Any time we need to access any information in addition to the input value, we can use the context dictionary.
Quite handy! My dear vigilant readers might remember that we have used the loader_context parameter in the get_country_code function. This is where it comes into play.
As a final tweak, let’s specify the default output format for the scraped data. Add the following lines to the settings.py file:
| |
This is not required, but it makes our life easier with Jenkins. Nice, we have refactored the Spider and added Item Loaders to streamline the data extraction process. Let’s move on and deploy our Scrapy Spider on Jenkins.
🎩 Mr Jenkins, Let’s Crawl!
Now that we have all the improvements checked in to the sample repository, we can improve our Jenkins pipeline to run the actual Scrapy Spider. Here is the updated Jenkinsfile:
| |
Although the Jenkinsfile is quite similar to the previous one, there are some notable changes.
Checkout Stage
Having my public GitHub repository, we can now clone it, so the Jenkins agent can access the Spider code.
Pre-Flight Stage
No changes here, we still check the Python and Scrapy versions.
Scrape Website Stage
The most significant change is the shell command: sh 'cd iphone_price_bot && scrapy crawl apple_website_spider'. This command navigates to the iphone_price_bot directory and runs the Scrapy Spider. If the DRY_RUN parameter is set to true, the Spider will not run.
Archive Stage
If everything goes well, we will have the outcome of the scraping job in the iphone_prices.csv file. We archive this file to keep track of the scraped data.
This way, we can easily access the scraped data from the Jenkins UI.
Let’s run the job and see what happens!
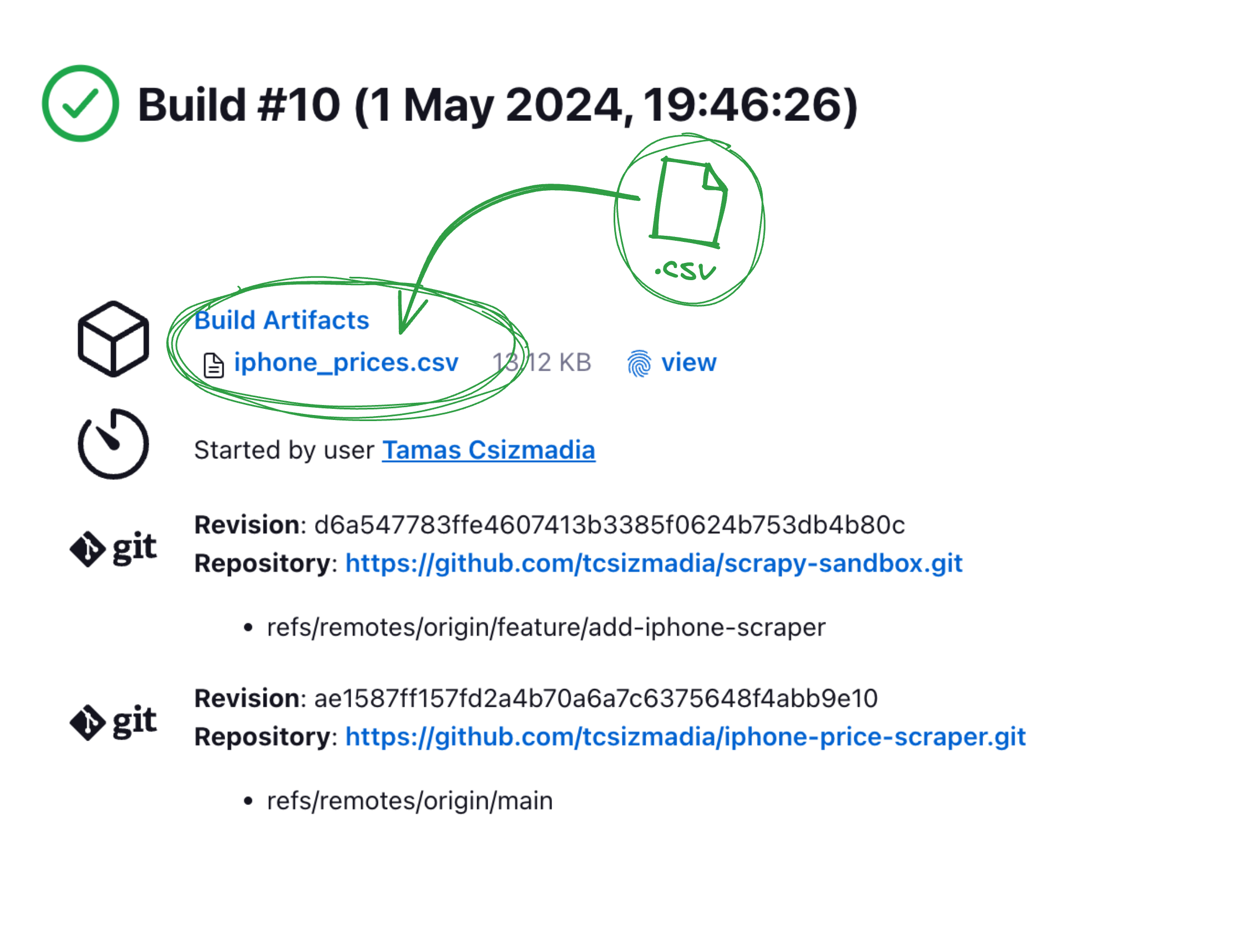
The job has run successfully, and we can see the iphone_prices.csv file in the Jenkins UI. We can download it and inspect the scraped data.
Open it in your favourite spreadsheet editor and do some analysis!
Where Can I Buy the Cheapest iPhone 14?
I wanted to find out where I could buy a blue iPhone 14 with 256 GB storage without spending too much money. 💰
 Source: Apple
Source: Apple
So, I opened the iphone_prices.csv file and filtered the data to ‘iPhone 14’ only, with the colour ‘Blue’ and the capacity of ‘256 GB’.
Here is what I’ve found:
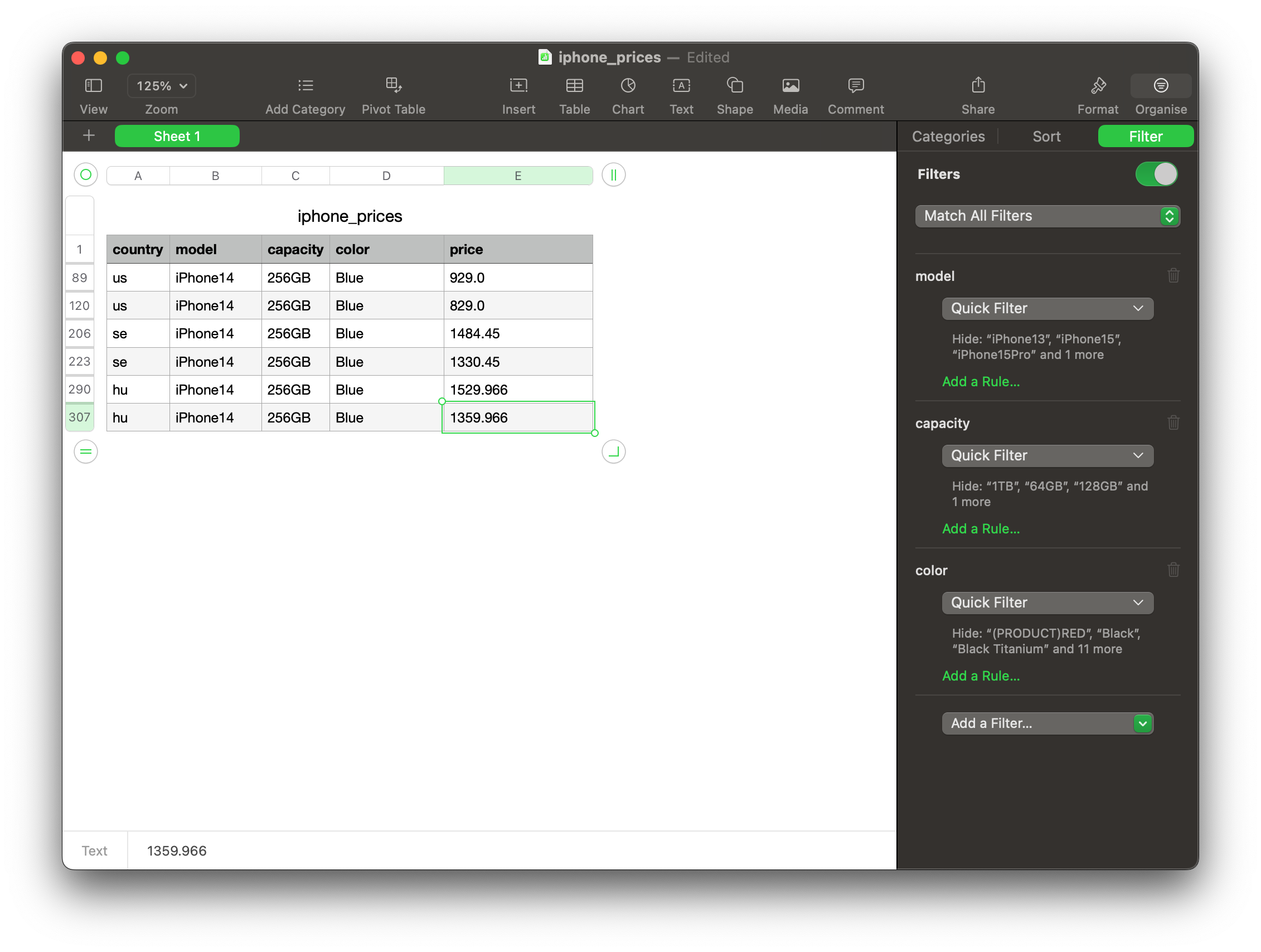
It seems that the iPhone 14 with 256 GB storage and blue colour is the cheapest in the US, and unfortunately, it costs much-much more in Hungary. 😭
🔬 Conclusion
In this series, we have learned how to scrape the web with Scrapy and make the process more efficient and streamlined with Jenkins. We have refactored the Spider to make it scalable and more maintainable. We have used Item Loaders to extract and clean the data more effectively. We have also used Item Pipelines to process the scraped data and make it production-ready. Finally, we have deployed the Scrapy Spider on Jenkins and automated the scraping process.
As we wrap up, I hope this series has been both informative and enjoyable. 🙏 It’s clear that what we’ve explored is merely the beginning — only the tip of the iceberg. With the insights and techniques you’ve acquired, I’m confident you’ll craft more sophisticated Spiders, extract really valuable data, and derive meaningful conclusions to guide your decisions. 👓